Overview
This was one of my first projects. Building a Sudoku game from scratch using just HTML and JavaScript was an incredibly rewarding and challenging experience. I started with the fundamental goal of creating a clean, interactive game that could both generate random puzzles and allow users to input their own answers. This project not only tested my technical skills but also helped me improve my problem-solving abilities and attention to detail.HTML Structure
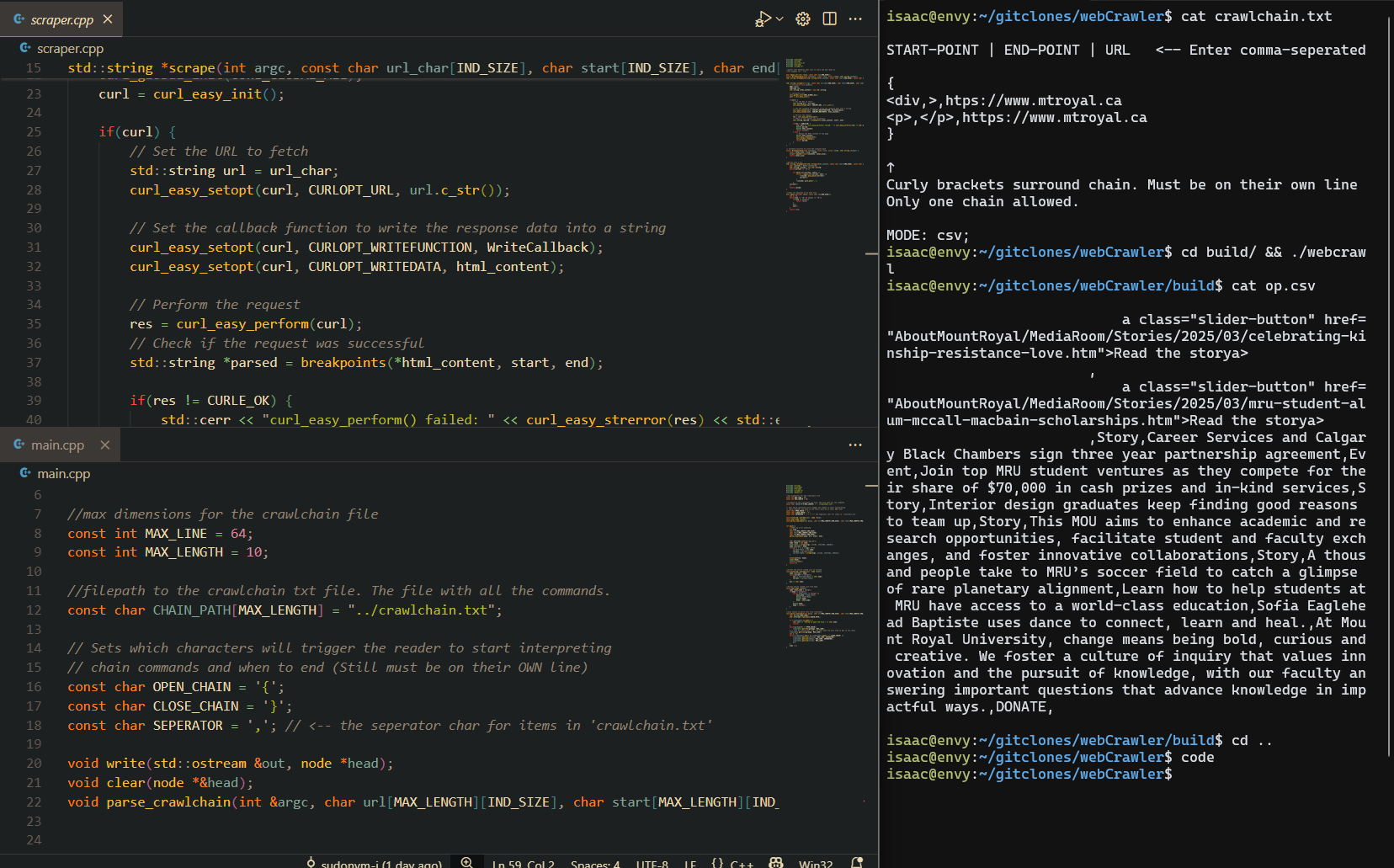
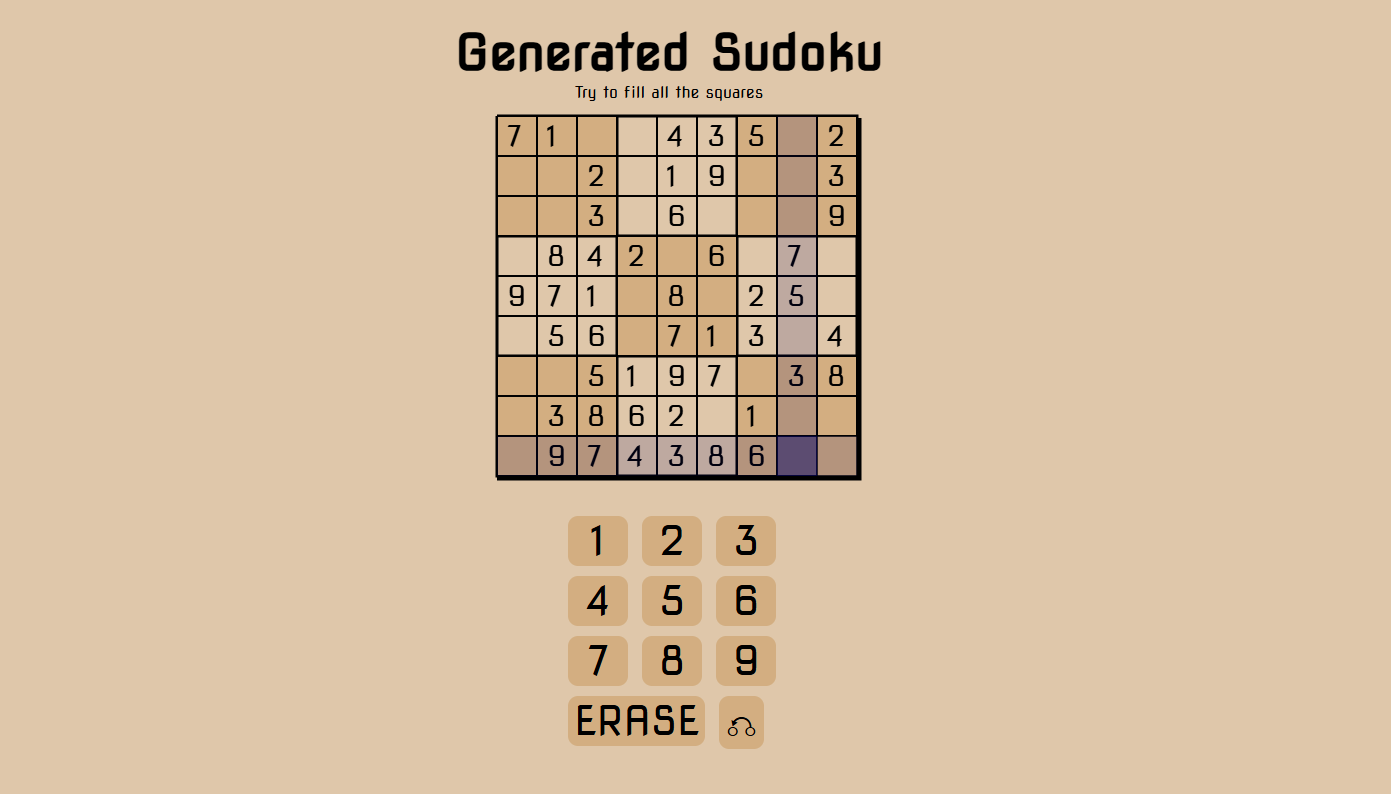
The first step was designing the game layout using HTML. I created a 9x9 grid using a combination of `` elements, where each cell would hold either a number or be left empty for user input. Each cell was individually clickable to allow for interaction, and I used HTML’s `input` fields to capture the numbers users entered. This allowed me to create the board structure and set the foundation for the game mechanics.
1. **Generate Random Sudoku Puzzles**: I created a random puzzle generator using an algorithm that would ensure the puzzle had a unique solution. This was crucial to ensure that the puzzles were solvable and provided a challenge to players.
2. **User Input Validation**: I built a validation function that would check whether the user’s input was correct based on Sudoku rules (no repeating numbers in any row, column, or 3x3 subgrid). This was one of the more complex parts of the project since it required checking all three constraints for each number entered.
3. **Check Puzzle Solving**: I also implemented a function to check if the user had solved the puzzle correctly. If all constraints were met and the board was filled, the game would notify the user of their success.
4. **Backtracking Algorithm**: For solving the puzzle, I implemented a backtracking algorithm. While this was an optional feature, it added significant complexity to the project and allowed the game to not only generate random puzzles but also solve any given Sudoku grid.
My Experience Creating an iterative Encryption Algorithm from scratch in Python
In my recent project, I set out to create an encryption algorithm from scratch using Python. My main goal was to develop an encryption method that could transform text in a unique, non-repetitive way using an iterative series. The concept behind the algorithm was to apply a series of transformations to each character in a message, where each iteration would change the pattern of encryption for the next character, ensuring no repetitions in the encryption.
Designing the Algorithm
I began by brainstorming how I wanted to structure the encryption process. My main idea was to avoid the predictability found in traditional encryption methods like Caesar cipher, which shifts characters by a fixed number. I wanted my algorithm to use an iterative approach that altered the encryption for each character based on previous ones.
The design concept involved using an iterative series of operations. For example, each character in the string would be processed using a combination of operations: shifting characters by varying amounts, changing their positions, and applying simple mathematical transformations like addition or subtraction of numbers derived from the character’s index. Each of these transformations would depend on a previously computed value, creating a cascading effect where the encryption evolves as the algorithm progresses.
Coding the Algorithm
Once I had the general idea, I began coding the algorithm in Python. The basic steps were:
Initial Setup: I decided that the algorithm should start with a secret key (a number or string) that would influence the transformation of the first character. This key would then be iterated on for each subsequent character, ensuring no repetitive transformations across the text.
Iterative Transformation: For each character in the input string, I created a function that would apply the transformation based on the iteration number. For instance:
The first character would have a specific shift based on the key.
The second character’s transformation would depend on the result of the first one, and so on. This allowed me to create a series of transformations that were tightly coupled to the evolving pattern.
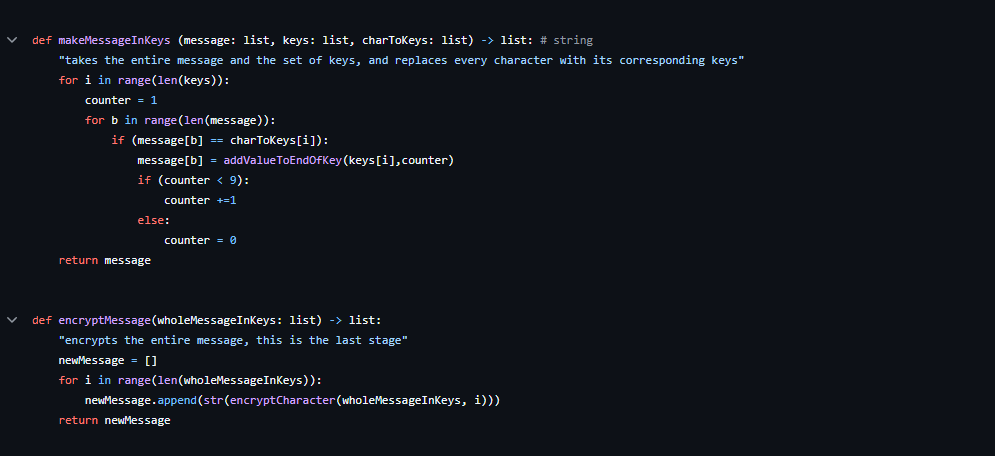
Character Encoding: I used Python's built-in ord() and chr() functions to convert characters to their ASCII values, perform the encryption calculations, and then convert them back into characters. This enabled me to easily manipulate the characters and apply mathematical transformations.
Decryption: I also built in a method for decryption, which would reverse the iterative transformations by applying the inverse of each operation used in the encryption.
Challenges Faced
One of the challenges I encountered was ensuring that the series of transformations was both secure enough to prevent easy decryption, while still being efficient. I had to carefully balance the complexity of the transformations and the iterative nature of the algorithm so that the encrypted message wouldn’t become too difficult to manage.
I also had to ensure that the key used in the algorithm wasn’t too simple, as that would defeat the purpose of creating a non-repetitive encryption scheme. I ended up using a combination of a numeric key and the length of the input string to generate a series of shifts for each character.
Another challenge was testing the algorithm. Ensuring that the iterative transformations worked as expected for different input strings took a fair amount of trial and error. Some edge cases required additional checks to avoid errors such as attempting to shift a character beyond the ASCII range.
Final Outcome
In the end, I was able to create a functional encryption algorithm that was both simple and unique. The algorithm successfully encrypts text using an iterative series of transformations that ensures no repetitive patterns in the encryption process. The result is an encrypted string that appears random and secure, yet can be decrypted with the correct key.
I was pleased with how well the algorithm worked, especially given the fact that it was designed to be both easy to implement and somewhat effective at hiding the original message. While this encryption method is certainly not suitable for high-security applications, it provided valuable insights into how iterative transformations can create non-repetitive encryption schemes.
JavaScript Logic
The most intricate part of the project was implementing the game logic with JavaScript. I needed to:1. **Generate Random Sudoku Puzzles**: I created a random puzzle generator using an algorithm that would ensure the puzzle had a unique solution. This was crucial to ensure that the puzzles were solvable and provided a challenge to players.
2. **User Input Validation**: I built a validation function that would check whether the user’s input was correct based on Sudoku rules (no repeating numbers in any row, column, or 3x3 subgrid). This was one of the more complex parts of the project since it required checking all three constraints for each number entered.
3. **Check Puzzle Solving**: I also implemented a function to check if the user had solved the puzzle correctly. If all constraints were met and the board was filled, the game would notify the user of their success.
4. **Backtracking Algorithm**: For solving the puzzle, I implemented a backtracking algorithm. While this was an optional feature, it added significant complexity to the project and allowed the game to not only generate random puzzles but also solve any given Sudoku grid.
Challenges
One of the biggest challenges I faced was ensuring the user’s input was validated correctly and efficiently. For example, handling edge cases like entering invalid characters or not filling in all the empty cells before checking the solution required careful logic. Additionally, managing the state of the board while providing real-time feedback (like highlighting incorrect numbers) was a tricky task, but one that greatly improved the user experience.Final Thoughts
The project gave me an immense sense of accomplishment, and I learned a great deal in the process, especially about using JavaScript for game logic and managing dynamic content with HTML and CSS. While the game itself is relatively simple, building it entirely from scratch gave me a deep understanding of how games are structured and how to balance both the user interface and logic to create a functional and enjoyable experience.Cypher-space
My Experience Creating an iterative Encryption Algorithm from scratch in Python
In my recent project, I set out to create an encryption algorithm from scratch using Python. My main goal was to develop an encryption method that could transform text in a unique, non-repetitive way using an iterative series. The concept behind the algorithm was to apply a series of transformations to each character in a message, where each iteration would change the pattern of encryption for the next character, ensuring no repetitions in the encryption.
Designing the Algorithm
I began by brainstorming how I wanted to structure the encryption process. My main idea was to avoid the predictability found in traditional encryption methods like Caesar cipher, which shifts characters by a fixed number. I wanted my algorithm to use an iterative approach that altered the encryption for each character based on previous ones.
The design concept involved using an iterative series of operations. For example, each character in the string would be processed using a combination of operations: shifting characters by varying amounts, changing their positions, and applying simple mathematical transformations like addition or subtraction of numbers derived from the character’s index. Each of these transformations would depend on a previously computed value, creating a cascading effect where the encryption evolves as the algorithm progresses.
Coding the Algorithm
Once I had the general idea, I began coding the algorithm in Python. The basic steps were:
Initial Setup: I decided that the algorithm should start with a secret key (a number or string) that would influence the transformation of the first character. This key would then be iterated on for each subsequent character, ensuring no repetitive transformations across the text.
Iterative Transformation: For each character in the input string, I created a function that would apply the transformation based on the iteration number. For instance:
The first character would have a specific shift based on the key.
The second character’s transformation would depend on the result of the first one, and so on. This allowed me to create a series of transformations that were tightly coupled to the evolving pattern.
Character Encoding: I used Python's built-in ord() and chr() functions to convert characters to their ASCII values, perform the encryption calculations, and then convert them back into characters. This enabled me to easily manipulate the characters and apply mathematical transformations.
Decryption: I also built in a method for decryption, which would reverse the iterative transformations by applying the inverse of each operation used in the encryption.
Challenges Faced
One of the challenges I encountered was ensuring that the series of transformations was both secure enough to prevent easy decryption, while still being efficient. I had to carefully balance the complexity of the transformations and the iterative nature of the algorithm so that the encrypted message wouldn’t become too difficult to manage.
I also had to ensure that the key used in the algorithm wasn’t too simple, as that would defeat the purpose of creating a non-repetitive encryption scheme. I ended up using a combination of a numeric key and the length of the input string to generate a series of shifts for each character.
Another challenge was testing the algorithm. Ensuring that the iterative transformations worked as expected for different input strings took a fair amount of trial and error. Some edge cases required additional checks to avoid errors such as attempting to shift a character beyond the ASCII range.
Final Outcome
In the end, I was able to create a functional encryption algorithm that was both simple and unique. The algorithm successfully encrypts text using an iterative series of transformations that ensures no repetitive patterns in the encryption process. The result is an encrypted string that appears random and secure, yet can be decrypted with the correct key.
I was pleased with how well the algorithm worked, especially given the fact that it was designed to be both easy to implement and somewhat effective at hiding the original message. While this encryption method is certainly not suitable for high-security applications, it provided valuable insights into how iterative transformations can create non-repetitive encryption schemes.